

My Adventures in Taming Metadata: A Media & Entertainment Journey
Alright, folks, let me tell you about my recent deep dive into the wonderful world of metadata, specifically in the context of media and entertainment. Buckle up, it’s a bit of a bumpy ride, but hopefully, you’ll learn something from my…uh…experiences.
So, it all started when I got tasked with, you know, “optimizing our content library.” Sounds fancy, right? Basically, our media asset management system was a hot mess. Files were named things like “Final_Final_V3_*,” and finding anything took longer than watching the actual movie. Metadata was either missing entirely or was just…wrong. Like, a documentary about penguins tagged as a romantic comedy. Seriously.


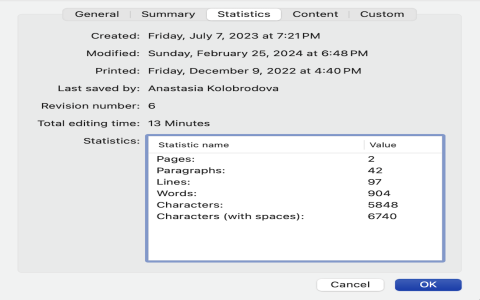
First things first, I had to figure out what metadata we actually needed. I started by talking to everyone: the editors, the marketing team, the archivists (those guys are goldmines of info!). I compiled a list of essential fields – things like title, description, keywords, genre, actors, director, production company, release date, and copyright information. Then I realized we also needed technical metadata – things like resolution, frame rate, codec, and audio channels. The list just kept growing!
Next up: Choosing a standard. There are a bunch of metadata standards out there, like Dublin Core, PBCore, and EBU Core. I spent days reading documentation and comparing features. Ultimately, we decided to go with a combination: EBU Core for the broadcast-specific stuff and a custom schema for our internal needs. It felt like over-engineering at first, but trust me, it saved us a lot of headaches down the road.
Okay, now the fun part: actually implementing the metadata schema. Our asset management system had a built-in metadata editor, but it was clunky and slow. So, I started looking at APIs and scripting tools. I ended up writing a Python script that could read metadata from CSV files and automatically populate the fields in our system. It wasn’t pretty, but it got the job done. Think duct tape and prayers, you know?
Of course, no system is perfect. One of the biggest challenges was dealing with legacy content. We had thousands of files with little to no metadata. I tried a few automated tools that promised to extract metadata from the content itself, but they were only partially successful. In the end, I had to hire a team of interns to manually review and tag the older content. It was tedious, but necessary.
- Step 1: Talk to everyone. Seriously, everyone.
- Step 2: Define your metadata requirements clearly.
- Step 3: Choose a standard (or a combination) that fits your needs.
- Step 4: Automate as much as possible.
- Step 5: Don’t be afraid to get your hands dirty (or hire interns).
Another issue I ran into was metadata consistency. Even with a defined schema, people still interpreted things differently. One person’s “action” was another person’s “adventure.” To solve this, I created a controlled vocabulary – a list of approved terms and values. It was a pain to maintain, but it ensured that everyone was on the same page.
Finally, I had to think about metadata governance. Who was responsible for creating, updating, and maintaining the metadata? I worked with the IT department to implement access controls and workflows to ensure that only authorized users could make changes. I also created a training program to educate everyone on the importance of metadata and how to use the system properly.
So, yeah, that’s my metadata journey in a nutshell. It was a long and winding road, full of challenges and setbacks. But in the end, we managed to transform our content library from a chaotic mess into a well-organized and easily searchable resource. It’s still a work in progress, but we’re moving in the right direction. My advice? Start small, be patient, and don’t be afraid to experiment. And always, always back up your metadata!
Now, if you’ll excuse me, I need to go rename some files… “Final_Final_V4_*,” anyone?










{kind=link}